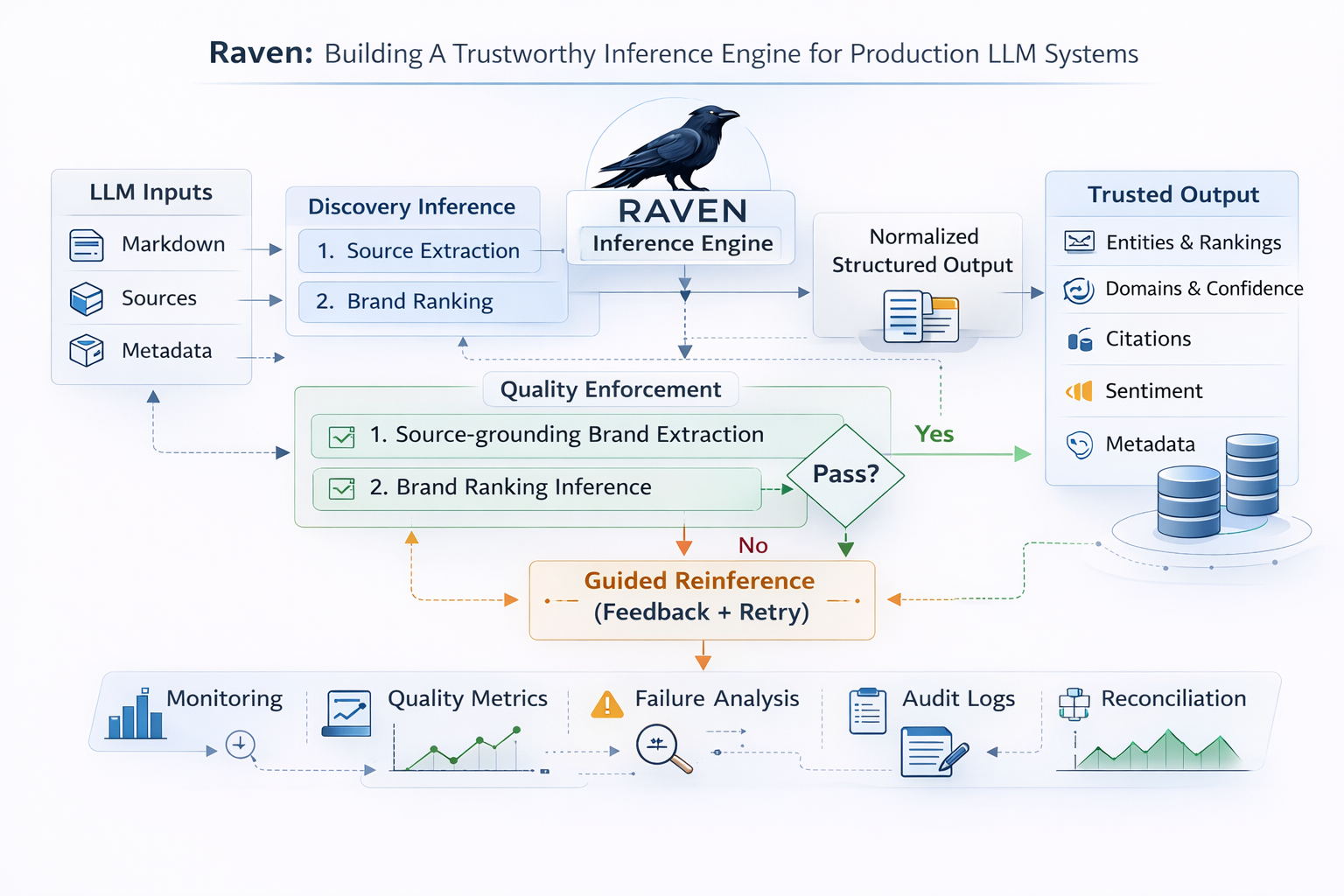
Beyond Dashboards: A Five-Layer Architecture for Proactive AI Search Visibility

Abstract
AI search has become a primary discovery layer. Billions of queries now flow through systems that synthesize narrative answers instead of returning ranked links. In this environment, brands compete for inclusion probability and narrative framing, not page position.
Most visibility tools respond to this shift with reactive dashboards: they log what models said, then surface changes after they have already occurred. This is structurally insufficient. By the time a citation shift appears in output snapshots, the upstream signals that caused it (authority graph changes, competitor content velocity, descriptor reinforcement) may have been forming for weeks.
This paper argues that AI visibility is an engineering problem, not a reporting problem. It outlines a five-layer architecture for moving from monitoring to orchestration: continuous signal ingestion, influence graph modeling, embedding-based narrative drift detection, confidence-weighted recommendations, and governed execution with closed-loop feedback.
1. From Ranking to Retrieval-Augmented Synthesis
Traditional search engines retrieve and rank indexed documents. Ranking algorithms consider hundreds of signals, but the output remains positional. A page appears at position one, two, or three. Visibility can be measured in discrete terms.
Large language models do not operate in this way. When a user submits a query, the system retrieves relevant documents through embedding similarity and ranking layers, then synthesizes a narrative response. Inclusion is not binary in the same sense as search ranking. It is probabilistic. A brand may appear in one synthesis and be absent in another, depending on contextual weighting.
This matters because of how retrieval-augmented generation (RAG) works under the hood. Before a model generates a response, a retrieval layer selects which documents make it into the context window. That selection is shaped by embedding similarity, authority signals, recency, and context filtering. Sources that do not pass retrieval never reach the generation phase, regardless of their quality. Research on RAG architectures confirms this layered filtering: one survey identifies three paradigms (Naive, Advanced, and Modular RAG) with increasingly sophisticated retrieval and augmentation mechanisms, while another categorizes designs as retriever-centric, generator-centric, hybrid, and robustness-oriented, noting that retrieval optimization directly determines which documents survive into generation.
The practical consequence: small shifts in document authority, recency, or semantic reinforcement can change which sources are retrieved, and therefore which brands appear in the synthesized output. This creates a dynamic environment in which narrative weight becomes the key competitive variable.
Narrative weight refers to the cumulative influence of distributed ecosystem signals that increase the likelihood of inclusion and favorable framing in model outputs.
Ranking vs. synthesis: structural comparison
| Dimension | Traditional search ranking | AI-native synthesis |
|---|---|---|
| Output format | Ordered list of links | Narrative response with optional citations |
| Visibility unit | Position (rank 1, 2, 3...) | Inclusion probability and framing |
| Measurement | Impressions, CTR, rank position | Citation frequency, narrative accuracy, mention context |
| Competitive dynamic | Displacement (one page replaces another) | Probabilistic weighting (multiple sources blended) |
| Stability | Relatively stable between index updates | Variable across runs, models, and query formulations |
2. Why Reactive Monitoring Is Insufficient
The distinction between reactive and proactive is not about sophistication of tooling. It is about which question the system is designed to answer.
Reactive systems answer: what did the model say at a specific moment in time?
Proactive systems answer: what ecosystem signals are currently forming that will influence what the model says next?
Most AI visibility tools today answer only the first question. They track brand mentions, citation frequency, and descriptive accuracy across models. These outputs are valuable, but structurally retrospective.
2.1 The ecosystem inputs that shape synthesis
Large language models synthesize across evolving corpora that include:
- Publisher coverage and editorial framing
- Technical documentation and product specifications
- Product comparisons and review aggregations
- Community discussions (Reddit, Stack Overflow, Hacker News)
- Structured data (schema markup, knowledge graphs)
- Backlink authority networks and citation graphs
- Funding announcements, press cycles, and earned media
None of these inputs operates in isolation. Authority graph changes amplify content velocity; community discourse reinforces editorial framing; structured data shapes how retrieval layers interpret entity relationships. The compounding effect means that shifts in narrative weight often build across multiple input channels simultaneously.
2.2 The latency problem
Reactive monitoring detects increased competitor inclusion after synthesis patterns have already adapted. In categories where competitive shifts occur rapidly, waiting for output changes before responding may mean reacting several weeks late.
Consider the sequence: a competitor publishes a series of technical benchmarks, industry analysts reference them, community forums discuss them, and high-authority domains link to them. Each of these signals incrementally shifts retrieval probability. By the time the model's output visibly changes, the ecosystem has already moved. A reactive dashboard captures the symptom weeks after the cause.
2.3 The reliability problem
Even when a reactive system detects a change quickly, it cannot trust what it sees. The Tow Center for Digital Journalism tested eight AI search engines and found that tools collectively produced inaccurate citations in over 60% of tests, with ChatGPT Search failing 67% of the time and Perplexity failing 37% of the time. The citation surface that reactive dashboards monitor is itself unreliable. A brand might appear to lose visibility when the model simply hallucinated a different source, or appear stable while the underlying retrieval ranking has already shifted.
This compounds the latency problem: a reactive system is not just slow, it is slow and noisy. Teams must first determine whether a detected change is real or a citation artifact before they can act on it. By that point, the upstream ecosystem signals that drove the actual shift may have been forming for weeks.
Seerly's monitoring layer addresses this by separating retrieval presence from citation accuracy. Rather than treating every output change as a signal, it gives teams the ability to distinguish pipeline-level breakdowns from surface-level noise, providing the reliable measurement foundation that proactive systems require.
3. AI Search as Ecosystem-Level Probabilistic Reasoning
Sections 1 and 2 established two things: AI synthesis is driven by layered retrieval (not ranking), and reactive monitoring of the output surface is both slow and unreliable. The natural next question is: what should a system actually measure?
The answer requires understanding how ecosystem signals translate into retrieval decisions. Section 2.1 listed the categories of content that feed synthesis (publisher coverage, documentation, community discussions, etc.). This section examines how models weight those inputs to produce the narrative the user sees.
3.1 How models weight ecosystem signals
Within the RAG pipeline, not all retrieved documents contribute equally to synthesis. Models apply implicit weighting based on:
- Recency relative to query intent: newer sources carry more weight for time-sensitive queries
- Cross-domain citation consistency: claims reinforced by multiple independent sources are more likely to survive into the generated response
- Domain authority proxies: trust signals inherited from retrieval layers bias selection toward established sources
- Embedding similarity within query clusters: documents that are semantically closer to the query intent rank higher in retrieval
- Descriptor repetition: when multiple unrelated sources use the same terminology for a brand, models treat it as consensus
3.2 Narrative weight is dynamic
Narrative weight is not static. It fluctuates as content velocity, authority distribution, and query demand shift. In probabilistic systems, inclusion likelihood may change gradually before becoming visibly noticeable.
The Reuters Institute's 2026 predictions report illustrates this directly: news organizations now forecast a 40% decline in search referrals over the next three years, with publishers planning to invest more in understanding AI chatbot distribution (+61 percentage points) while cutting back on traditional search optimization (-25 percentage points). As publishers shift their strategies, the content they produce, how they structure it, and where they distribute it will change. This reshapes the retrieval corpus that models draw from, which in turn shifts narrative weight for every brand in affected categories. A team measuring only their own citation frequency would miss this entirely.
Therefore, the correct strategic question is not merely whether a brand appears in AI outputs. It is how narrative weight is distributed across relevant query clusters and how that distribution trends over time.
3.3 Scale of the shift
The following table consolidates the key adoption and displacement metrics referenced throughout this paper.
| Metric | Value | Source |
|---|---|---|
| ChatGPT weekly active users | 900M | TechCrunch (Feb 2026) |
| ChatGPT daily requests | 2.5B | Backlinko (Feb 2026) |
| Google AI Overviews monthly reach | 2B users, 200+ countries | Google/TechCrunch (Jul 2025) |
| AI Overviews query coverage (peak) | ~25% of queries | WordStream / Semrush (Jul 2025) |
| Organic CTR drop when AI Overviews present | -61% | Dataslayer (Sep 2025) |
| Zero-click search share | 69% (up from 56% in May 2024) | Similarweb (May 2025) |
| Global Google search referrals change | -33% YoY | Press Gazette / Reuters (2025) |
| U.S. Google search referrals change | -38% YoY | Press Gazette / Reuters (2025) |
| Gartner forecast: search volume drop by 2026 | -25% | Gartner (Feb 2024) |
| Gartner forecast: organic traffic drop by 2028 | -50%+ | Gartner (Dec 2023) |
4. Engineering a Proactive Visibility Architecture
A proactive AI-native visibility framework requires layered system design. At a minimum, five architectural components are necessary: signal ingestion, influence modeling, narrative drift detection, recommendation engines, and governed execution.
4.1 Continuous External Signal Ingestion
The first layer expands monitoring beyond brand-level outputs to ecosystem-level intelligence.
This includes:
- Model output snapshots: Periodic sampling of AI model outputs across structured and dynamically expanding query sets, versioned and timestamped for longitudinal comparison
- Competitor content diffing: Structural change detection on competitor documentation, product pages, and technical content using semantic diffing (not just byte-level)
- Authority graph monitoring: Tracking high-authority backlink graph changes, new citing domains, and shifts in domain authority distributions
- Emerging query detection: Identification of new query clusters using trend APIs, search console data, and community discourse analysis
- Publisher coverage tracking: Monitoring editorial coverage, review publications, and industry analyst mentions
- Community discourse ingestion: Semantic clustering of discussions on Reddit, Stack Overflow, Hacker News, and relevant forums
Each signal must be timestamped and versioned. Without historical baselines, drift cannot be quantified. Snapshot-based storage enables longitudinal comparison across weekly or biweekly intervals. Seerly implements this through structured prompt libraries with scheduled runs and citation diffs, providing the baseline data that makes drift detection and influence modeling possible.
At scale, ingestion pipelines require distributed task queues, idempotent ingestion logic, and normalized storage schemas. Event-driven connectors can capture high-velocity changes from APIs, while scheduled crawlers handle structured updates.
4.2 Influence Graph Modeling
Raw signals do not constitute insight. The second layer translates ecosystem movement into measurable influence.
A graph-based model represents:
- Domains (with authority scores and content velocity)
- URLs (with citation frequency and recency)
- Brands (with descriptor associations and sentiment)
- Query clusters (with intent classification and competitive density)
Edges represent citation relationships, semantic similarity, or co-occurrence frequency. Node weights incorporate dimensions such as citation frequency across models, cross-model consistency, recency decay, and domain authority proxies.
For example, if a domain's citation frequency increases by 30-40% across multiple major models within a 30-day window, and that domain aligns semantically with a competitor's feature set, the system flags influence escalation.
This transforms visibility measurement from simple mention counting into ecosystem power distribution analysis.
Influence graph dimensions
| Node type | Key attributes | Edge types |
|---|---|---|
| Domain | Authority score, content velocity, citation frequency | Cites, cited-by, co-cited-with |
| URL | Freshness, word count, structured data presence | Linked-from, semantically-similar-to |
| Brand | Descriptor set, sentiment distribution, category placement | Mentioned-in, compared-with |
| Query cluster | Intent class, volume trend, competitive density | Answered-by, retrieves-from |
4.3 Narrative Drift Detection Using Embedding Comparison
Quantitative citation growth does not always capture qualitative narrative shifts. Embedding comparison techniques enable semantic drift measurement.
By converting model outputs into vector representations and calculating cosine similarity against historical baselines, organizations can detect narrative divergence. Research on semantic drift detection confirms that embedding-based cosine similarity remains the dominant approach for measuring meaning shifts over time, with subsequent work on threshold selection showing that thresholds must be calibrated per domain.
If cosine similarity falls below a defined threshold, such as 0.85 relative to a 90-day baseline, the system flags semantic drift.
This enables detection of:
- Descriptor changes: A brand previously described as "mid-market" starts appearing as "enterprise"
- Framing shifts: Product descriptions shift from "alternative to X" to "replacement for X"
- Category reclassification: A tool previously categorized as "analytics" begins appearing under "AI infrastructure"
- Sentiment drift: Neutral descriptions become evaluative (positive or negative)
These shifts can occur even when overall mention frequency remains stable, which is why embedding-based detection catches signals that citation counting alone misses. In practice, narrative drift often surfaces competitive repositioning weeks before it becomes visible in citation counts: a competitor being reframed from "alternative" to "leader" in model outputs is a strategic signal, not a statistical blip.
4.4 Confidence-Weighted Recommendation Systems
Automated interventions must be bounded by statistical confidence.
Each recommendation should include:
- Signal strength score: How strong is the underlying evidence?
- Cross-model agreement level: Is this pattern consistent across ChatGPT, Perplexity, Gemini, and others?
- Historical trend slope: Is this an accelerating or decelerating shift?
- Risk impact score: How much would inaction cost in terms of inclusion probability?
Composite confidence thresholds, for example 0.75 aggregated signal certainty, prevent overreaction to transient noise. Given the documented instability of citation systems (where the same query can produce different citations across runs), confidence weighting is essential to separate real ecosystem shifts from stochastic variance.
Recommendations may include:
- Documentation expansion aligned to emerging query clusters
- Schema adjustments to clarify category positioning
- Authority reinforcement strategies (earning coverage from high-authority domains)
- Targeted content development in high-growth clusters
- Terminology standardization to reduce citation errors
Agents generate drafts and simulations under constrained objectives, but execution remains governed.
4.5 Governed Execution and Feedback Loops
Autonomous execution introduces reputational and strategic risk. Governance layers should include:
- Brand alignment verification: Does this action reinforce or dilute brand positioning?
- Reputational risk scoring: Could this action be perceived as manipulative or misleading?
- Controlled deployment gating: Staged rollout with rollback capability
- Post-deployment impact correlation: Measuring whether the intervention produced the expected outcome
After structured changes are implemented, the system monitors subsequent snapshots. If inclusion probability improves by 10-15% across monitored query clusters within a 21-day window, correlation strengthens. If not, weighting models are recalibrated.
This creates a closed-loop adaptive system rather than a static dashboard.
Governance decision matrix
| Signal confidence | Recommendation type | Governance level |
|---|---|---|
| High (>0.85) | Content update, schema fix | Auto-approve with notification |
| Medium (0.65-0.85) | New content, authority strategy | Human review required |
| Low (<0.65) | Strategic repositioning | Executive approval required |
| Any | Brand-adjacent or competitive | Always human review |
5. Operational Implications
The five-layer architecture described above is not theoretical. Each layer addresses a specific operational gap that exists in current practice.
5.1 The cost of manual processes
Without automated ingestion and modeling, AI visibility audits are manual. A single audit cycle across several hundred structured queries may require 20-40 hours, including model sampling, citation extraction, comparative analysis, and strategic interpretation. At the pace of ecosystem change documented above, a monthly manual cycle means operating with 3-4 week old data in a system that shifts weekly.
5.2 What automation changes
Automated ingestion and modeling systems reduce human workload to reviewing high-confidence recommendations rather than performing raw data collection.
More importantly, proactive systems can surface ecosystem shifts within 7-10 days of upstream signal formation, compared to 30-day or longer reactive cycles common in manual processes.
In probabilistic reasoning systems, speed of adaptation materially affects competitive inclusion probability. Seerly provides the measurement foundation for this transition: structured prompt-set management, citation frequency tracking, and attribution correctness analysis that separates retrieval presence from citation accuracy. This reliable baseline is what makes proactive signal ingestion and drift detection possible, because you cannot detect meaningful shifts without first knowing what accurate measurement looks like.
5.3 What measurement should look like
Building on the measurement framework outlined in our companion paper on citation mechanics, teams operating proactive visibility systems should track:
| Metric | What it measures | Proactive vs. reactive |
|---|---|---|
| Citation frequency | % of prompt runs with brand citation | Reactive (output measurement) |
| Citation placement | Primary vs. secondary source positioning | Reactive (output measurement) |
| Attribution correctness | Whether citations point to right pages with right claims | Reactive (quality measurement) |
| Ecosystem signal velocity | Rate of change in upstream authority, content, and coverage | Proactive (input measurement) |
| Narrative drift score | Cosine similarity of brand descriptions vs. baseline | Proactive (semantic measurement) |
| Competitive influence delta | Change in competitor citation share across query clusters | Proactive (competitive measurement) |
| Recommendation confidence | Aggregated certainty of system recommendations | Proactive (decision quality) |
Conclusion
Billions of queries now flow through AI synthesis systems. ChatGPT alone serves 900 million weekly active users; Google AI Overviews reach 2 billion. The discovery layer has shifted from ranking documents to generating narratives, and with it, the competitive variable has changed from page position to narrative weight.
This paper identified two structural failures in reactive monitoring: it is slow (detecting shifts weeks after upstream signals have already moved) and noisy (the citation surface itself is wrong over 60% of the time). Together, these make reactive dashboards insufficient as a primary visibility strategy.
The five-layer architecture proposed here addresses both problems at their root. Signal ingestion captures ecosystem movement as it forms. Influence graph modeling quantifies how that movement redistributes authority. Embedding-based drift detection surfaces qualitative narrative shifts that citation counting misses. Confidence weighting prevents overreaction to noise. And governed execution closes the loop between detection and response.
The prerequisite for all of this is reliable measurement. Without the ability to separate retrieval presence from citation accuracy, every layer above it operates on uncertain data. Seerly provides this foundation: structured prompt-set management, citation tracking, and attribution correctness analysis that gives teams a trustworthy baseline. Proactive signal ingestion and drift detection build on top of that baseline, not instead of it.
The transition from monitoring to orchestration is not a tooling upgrade. It is an architectural shift in how organizations relate to AI-native discovery.
Further Reading
The research and data referenced throughout this paper draw from industry reports on AI search adoption, academic work on retrieval-augmented generation and semantic drift, and investigative journalism on citation reliability. The sources below provide deeper context for each of the architectural layers discussed.
- ChatGPT reaches 900M weekly active users - TechCrunch, Feb 2026. OpenAI's milestone announcement that underpins the scale-of-shift argument in section 3.3.
- Semrush AI Overviews Study: What 2025 SEO Data Tells Us - Semrush, 2025. Analysis of 10M+ keywords showing how Google's AI Overviews are reshaping search visibility across industries.
- Journalism, media, and technology trends and predictions 2026 - Reuters Institute, Jan 2026. Survey of 280 digital leaders forecasting a 40% decline in search referrals and a strategic pivot toward AI chatbot distribution.
- Gartner Predicts Search Engine Volume Will Drop 25% by 2026 - Gartner, Feb 2024. The widely cited forecast on search volume and organic traffic displacement that frames the urgency of proactive visibility.
- How to Rank in Google AI Overviews: 9 Data-Backed Strategies - Dataslayer, Nov 2025. Documents the 61% organic CTR drop when AI Overviews are present, based on analysis of 3,100+ queries.
- Retrieval-Augmented Generation for Large Language Models: A Survey - Gao et al., arXiv, 2023. Comprehensive survey identifying Naive, Advanced, and Modular RAG paradigms that inform the retrieval-layer analysis in section 1.
- Retrieval-Augmented Generation: A Comprehensive Survey of Architectures - Sharma et al., arXiv, 2025. Categorizes RAG designs as retriever-centric, generator-centric, or hybrid, with analysis of how retrieval optimization determines document survival.
- AI Search Has a Citation Problem - Columbia Journalism Review / Tow Center, Mar 2025. Investigative study finding over 60% error rates across eight AI search engines, central to the reliability argument in section 2.3.
- Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change - Hamilton et al., ACL, 2016. Foundational work on using embedding-based cosine similarity to measure meaning shifts over time, the basis for the drift detection approach in section 4.3.
- A Survey on Contextualised Semantic Shift Detection - Montanelli & Periti, arXiv, 2023. Surveys computational approaches for detecting semantic change, including threshold calibration methods referenced in the drift detection architecture.
- Google's AI Overviews have 2B monthly users - TechCrunch, Jul 2025. Reports AI Overviews reaching 2 billion monthly users by Q2 2025, up from 1.5 billion at Google I/O.
- Zero-Click Searches and How They Impact Traffic - Similarweb, 2025. Documents the rise in zero-click searches from 56% to 69% following the launch of Google AI Overviews.