Raven: Building a Trustworthy Inference Engine for Production LLM Systems
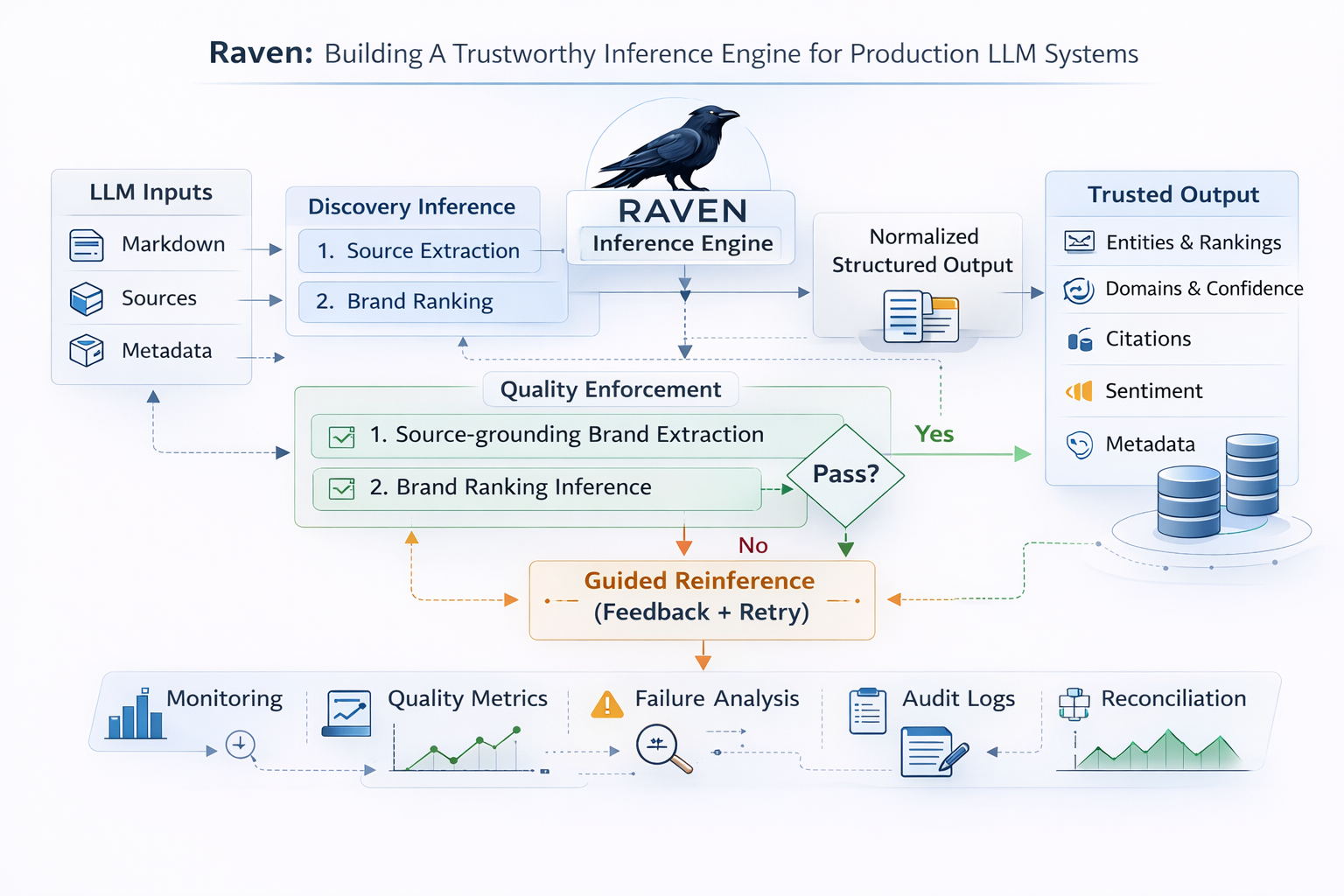
Raven: Building a Trustworthy Inference Engine for Production LLM Systems
Most LLM products fail in production at the same point: getting reliable output and consistently making sense of messy, unstructured data.
In our domain, the data is deeply unstructured, and making sense of it reliably is core to the product. That means inference is not just about parsing output, but about interpreting ambiguous signals in the most defensible way possible. In this setting, small extraction errors compound quickly, so structured output cannot just look plausible. It has to be consistently trustworthy.
That is the problem we built Raven to solve.
Raven is our inference engine for the AI discoverability pipeline. It is deliberately not optimized for minimum latency. It is optimized for correctness under messy real-world outputs. We accept extra inference passes when needed, because bad structured output is more expensive than slower output.
Why inference was the hard part
Upstream, we already had strong generation pipelines producing markdown responses and source metadata from multiple providers. But raw responses are not enough for analytics workflows. We needed to persist clean entities, rankings, citations, and sentiment in a way that powers diagnostics and reporting safely.
In practice, one-shot inference had recurring failure modes:
- hallucinated source URLs
- brand mentions without evidence in text
- omission of the primary project brand despite clear markdown presence
- malformed citation URLs that should never be persisted
- brittle outputs that looked valid at a glance but failed downstream expectations
The requirement became clear: inference had to be verification-driven, not just model-driven.
Raven architecture in production
Raven runs as a queue-backed step in our workflow system, with an orchestrator that executes two inference tracks in parallel:
- discovery inference
- sentiment inference
Each track is idempotent and independently tracked. If one fails and the other succeeds, the step still moves forward. We fail only when both fail. That gives us better resilience without hiding failure signals.
For discovery specifically, Raven uses a two-pass inference design:
-
Source-grounded extraction Extract brands per source using markdown and structured source context.
-
Brand ranking inference Rank explicitly mentioned brands and assign domains and confidence.
These two outputs are then merged into a normalized insight object before persistence.
This split is important. It lets us evaluate source fidelity and ranking logic separately instead of forcing one prompt to do everything.
The core design choice: verification over blind trust
The strongest signal in Raven is the quality loop.
After each inference call, Raven runs explicit quality checks against the generated structure. If those checks fail, Raven does not blindly retry. It generates targeted feedback, reflects on what went wrong, and re-runs inference with correction guidance informed by the failed checks.
There is a growing body of evidence that model outputs often improve when reflection is introduced into the loop, and we have seen the same pattern in our own testing. Coupled with explicit quality checks and guided feedback, this reflection-driven retry cycle materially reduces the error rate of final structured outputs and makes the system reliable enough for production use.
Retries are deliberately bounded so the system can improve reliability without turning latency and cost into unbounded failure modes.
This is an intentional tradeoff. It increases compute and response time, but materially improves the reliability of stored outputs.
What the quality layer enforces
Raven’s quality layer is designed to ensure that structured outputs remain grounded, internally consistent, and safe to persist.
At a high level, it verifies that inferred outputs stay anchored to the available source context, that ranked entities are supported by evidence in the response, and that primary project signals remain consistent with what is actually present in the underlying markdown and citations.
It also accounts for the kinds of inconsistencies that appear in real-world data, including noisy URL formats, partial matches, and minor source variations, using normalization and safe matching to avoid brittle failures.
The goal is not just to catch malformed outputs. It is to block the more dangerous class of results that appear plausible on the surface, but do not hold up under validation.
Reinference is guided, not blind retry
When checks fail, Raven does not simply try again.
Instead, it turns the failure into structured feedback for the next pass. The system identifies what did not hold up under validation, reflects on the failure pattern, and re-runs inference with targeted correction guidance.
This makes reinference a constrained self-correction cycle rather than a blind retry. The next attempt is shaped by explicit validation signals, not by random resampling.
This reflection-driven loop is important in practice. Both external research and our own testing show that model outputs often improve when reflection is paired with clear feedback. In Raven, that makes the retry path materially more reliable than a naive second attempt.
There is also an additional reinference path for specific edge cases. Even after multiple validation layers, we wanted a final safeguard for the small class of bad data that can still slip through. That additional pass acts as a targeted recovery mechanism, helping us correct escaped errors before they become persistent downstream issues.
Failed attempts are also retained for auditability, and quality metrics are emitted for operational visibility.
Structured parsing and persistence
After inference, responses are parsed and normalized before storage. This layer handles imperfect model behavior defensively:
- direct JSON parse with fallback extraction when needed
- schema-shape validation for required fields
- filtering of malformed citation entries
- normalization of sentiment into allowed values
- coercion of ranking fields into usable numeric positions where possible
Then insights are persisted into the structured entities that power downstream analytics, diagnostics, and recommendations.
This is the key operational outcome: inference stops being raw text and becomes a reliable data substrate for downstream systems.
Reliability and scale controls
Raven includes practical production controls around execution:
- queue-backed processing
- idempotent sub-job handling
- bounded concurrency
- batch processing across runs
- optional cache-aware execution paths
- non-blocking post-inference enrichment
None of these are flashy individually. Together they keep the inference step predictable and recoverable under production load.
Observability and operator feedback
RRaven emits metrics and events for:
- inference attempts
- per-check pass or fail and issue counts
- reinference starts and completions
- retry exhaustion
- final attempt counts and quality outcomes
This matters because quality regressions in inference are often gradual. We need visibility into trends, not just hard failures.
What Raven is and is not
Raven is not a low-latency response engine.
It is a verification-driven inference system designed for production data integrity. We intentionally spend extra time on validation, reflection, and correction because downstream analytics, diagnostics, and recommendations depend on trusted structure.
What Raven is and isn't
Raven is not a low-latency response engine.
It is a verification-driven inference system designed for production data integrity. We intentionally spend extra time on validation, reflection, and correction because downstream analytics, diagnostics, and recommendations depend on trusted structure.